# Librerías
library(forecast) # para predecir observaciones futuras. acf() y pacf()
library(ggplot2) # Nice plots
library(readxl) # Para leer excels
library(stats) # Para crear objetos ts()
library(tseries) # Para verificar estacionaridad de una serie | función adf.test()
library(purrr) # para mapSeries Temporales - ARIMA: Paro
Introducción
A continuación se va a explicar como modelizar una serie temporal con un ARIMA y todas las consideraciones que se deben tener en cuenta. Se llevará a cabo un ejemplo práctico a partir de un conjunto de datos, mostrando como interpretar los resultados que se van obteniendo.
dataset
En este cuaderno vamos a analizar el dataset llamado Paro.xlsx. Este dataset presenta los datos de paro por trimestre en España a partir del año 2013, posterior a la crisis económica de 2011.
Corresponde a la operación estadística del INE 30308 Encuesta de Población Activa (EPA). El objetivo de este estudio es intentar modelizar el número de parados a través de un modelo ARIMA y ver si realmente el número de parados se podría aproximar por este modelo sin tener en cuenta variables externas.
Parece razonable aclarar a priori el concepto de “parado” con el fin de entender que es lo que queremos modelizar. De acuerdo con el informe metodológico presentado por el INE:
Se considerarán paradas a todas las personas de 16 o más años que reúnan simultáneamente las siguientes condiciones:
estar sin trabajo, es decir, que no hayan tenido un empleo por cuenta ajena ni por cuenta propia durante la semana de referencia.
estar buscando trabajo, es decir, que hayan buscado activamente un trabajo por cuenta ajena o hayan hecho gestiones para establecerse por su cuenta durante el mes precedente.
estar disponibles para trabajar, es decir, en condiciones de comenzar a hacerlo en un plazo de dos semanas a partir del domingo de la semana de referencia.
También se consideran paradas las personas de 16 o más años que durante la semana de referencia han estado sin trabajo, disponibles para trabajar y que no buscan empleo porque ya han encontrado uno al que se incorporarán dentro de los tres meses posteriores a la dicha semana. Por lo tanto, en este caso no se exige el criterio de búsqueda efectiva de empleo.
Concretamente en este dataset tenemos las siguientes variables:
- Fecha: Fecha de medición del número de parados.
- Total: Número de parados en España en la fecha correspondiente.
Descripción del trabajo a realizar
Se pretende ajustar una serie temporal que contiene el número de parados mediante un modelo ARIMA.
- Explorar patrones en la serie temporal.
- Ver que la serie sea estacionaria.
- Aplicar diferenciación si es necesario para estacionarizar la serie.
- Identificar modelos ARIMA/SARIMA utilizando información de la exploración y funciones ACF y PACF.
- Ajustar varios modelos ARIMA/SARIMA y seleccionar el mejor según métricas de ajuste.
- Evaluar la significancia estadística de los coeficientes del modelo ARIMA.
- Interpretar los coeficientes para comprender su influencia en la serie temporal.
Análisis Exploratorio (EDA)
EDA viene del Inglés Exploratory Data Analysis y son los pasos relativos en los que se exploran las variables para tener una idea de que forma toma el dataset.
Librerías
En este apartado se van a cargar todas las librerías necesarias para ejecutar el resto del código. Se recomienda instalarlas en caso de no disponer de ellas.
Cargamos entonces el conjunto de datos:
data <- readxl::read_excel("../../../../files/paro.xlsx",
sheet = "Datos",
col_types = c("date", "numeric")
)sum(is.na(data))[1] 0Por otra parte, para tener una noción general que nos permita describir el conjunto con el que vamos a trabajar, podemos extraer su dimensión, el tipo de variables que contiene o qué valores toma cada una.
# Dimensión del conjunto de datos
dim(data)[1] 46 2# Tipo de variables que contiene
str(data)tibble [46 × 2] (S3: tbl_df/tbl/data.frame)
$ Fecha: POSIXct[1:46], format: "2024-04-01" "2024-01-01" ...
$ Total: num [1:46] 2755 2978 2861 2894 2808 ...ARIMA (AutoRegressive Integrated Moving Average)
Introducción
El modelo ARIMA es uno de los modelos más comunes y poderosos para el análisis de series temporales. Se utiliza para modelar y predecir datos que exhiben comportamientos de tendencia y estacionalidad.
- Componentes del modelo ARIMA:
AR (Auto-regresivo): Representa la relación entre una observación actual y un número determinado de observaciones anteriores (retardos). p es el componente autoregresivo, que indica cuántas observaciones pasadas influyen en la observación actual.
I (Integrated):. Representa el número de diferencias necesarias para hacer estacionaria la serie temporal. d es el número de diferenciaciones necesarias para hacer que la serie sea estacionaria. Esto se determina mediante pruebas estadísticas como el test de Dickey-Fuller aumentado (ADF test). Es importante tener cuidado de no sobrediferenciar la serie, lo que se puede observar en el gráfico de la función de autocorrelación (ACF) si los valores comienzan a ser negativos rápidamente.
MA (Media Móvil): Representa la relación entre una observación actual y un error de predicción residual de observaciones anteriores. q es el componente de media móvil, que indica cuántos términos de los residuos anteriores influyen en la observación actual.
Si la serie está ligeramente por debajo del nivel de diferenciación adecuado (subdiferenciada), se pueden agregar uno o más términos de AR adicionales. Por otro lado, si la serie está sobrediferenciada, se puede considerar agregar términos MA adicionales para mejorar el modelo.
Hasta ahora, hemos restringido nuestra atención a datos no estacionales y modelos ARIMA no estacionales. Sin embargo, los modelos ARIMA también son capaces de modelar una amplia gama de datos estacionales.
Un modelo SARIMA estacional se forma incluyendo términos estacionales adicionales en los modelos ARIMA que hemos visto hasta ahora. Está escrito de la siguiente manera:
Seasonal ARIMA (AutoRegressive Integrated Moving Average)
Un modelo ARIMA estacional se forma al incluir términos estacionales adicionales en los modelos ARIMA que hemos visto hasta ahora. Se escribe de la siguiente manera:
ARIMA(p, d, q)(P, D, Q)(m)donde (p,d,q) representa la parte no estacional del modelo, y (P,D,Q)la parte estacional. Además m sirve para indicar el número de observaciones que hay por año, es decir, el periodo.
PASOS GENERALES
Dibujar la serie Examina la serie en busca de características como tendencia y estacionalidad. Verifica si realmente existe un patrón estacional.
Diferenciar Vamos a calcular los valores de D,d (en ese orden)
- Si se observa componente estacional en 1), tomar la diferencia estacional de orden m,
ej: diff(tss,12), esto equivale a D=1, y dibujar. En caso de que la serie aun tenga tendencia, diferenciar ahora la componente no estacional las veces que sea necesario. - Si sólo hay componente no estacional, diferenciar la serie las veces que sea necesario hasta remover la tendencia, y ese será el parámetro d.
- Si no se observa ni componente estacional ni tendencia, no diferenciar.
- Si se observa componente estacional en 1), tomar la diferencia estacional de orden m,
Examinar ACF/PACF de las series diferencias (si es necesario) Para determinar los parámetros:
- Componente NO Estacional: Examinar los primeros lags (1,2,3,..). El número de picos sucesivos (o casi) en el ACF fuera de las bandas horizontales con un PACF que se reduce gradualmente indican MA no estacionales, determinando q. Lo mismo en la ACF indica p.
- Componente Estacional: Examinar los lags en múltiplos de m (Ej dato mensual 12,24,36,…). El número de picos sucesivos en el ACF fuera de las bandas horizontales con un PACF que se reduce gradualmente indican MA no estacionales, determinando Q. Lo mismo en la ACF indica P.
Generar todas las combinaciones posibles de parámetros con los candidatos seleccionados en los pasos anteriores. Alimentar todas las combinaciones en el algoritmo SARIMA.
Evaluar los resultados, revisando los residuos para los modelos propuestos anteriormente, viendo los residuos, AIC, BIC,…. En caso de no obtener buenos resultados, estudiar otra parametrización para el ARIMA/SARIMA.
En general, SARIMA requiere un ajuste de parámetros más metódico, pero puede aprender patrones más ricos. La selección de pedidos de ARIMA es más rápida pero menos sólida para las series estacionales.
Vamos a cargar los datos en un objeto adecuado para su análisis:
# Convertir el vector en una serie temporal
# ts() del paquete stats
tss <- ts(rev(data$Total), start = 2013, frequency = 4)
tss Qtr1 Qtr2 Qtr3 Qtr4
2013 6278.2 6047.3 5943.4 5935.6
2014 5933.3 5622.9 5427.7 5457.7
2015 5444.6 5149.0 4850.8 4779.5
2016 4791.4 4574.7 4320.8 4237.8
2017 4255.0 3914.3 3731.7 3766.7
2018 3796.1 3490.1 3326.0 3304.3
2019 3354.2 3230.6 3214.4 3191.9
2020 3313.0 3368.0 3722.9 3719.8
2021 3703.3 3586.4 3467.4 3148.7
2022 3214.7 2994.7 3025.8 3081.6
2023 3186.3 2808.2 2894.5 2860.8
2024 2977.9 2755.3 Análisis Descriptivo: Podemos realizar un análisis descriptivo básico para comprender mejor la serie temporal.
summary(tss) Min. 1st Qu. Median Mean 3rd Qu. Max.
2755 3214 3712 4026 4788 6278 plot(tss, main = "Parados en España")
legend("topright", legend = c("Total"), col = "black", lty = 1)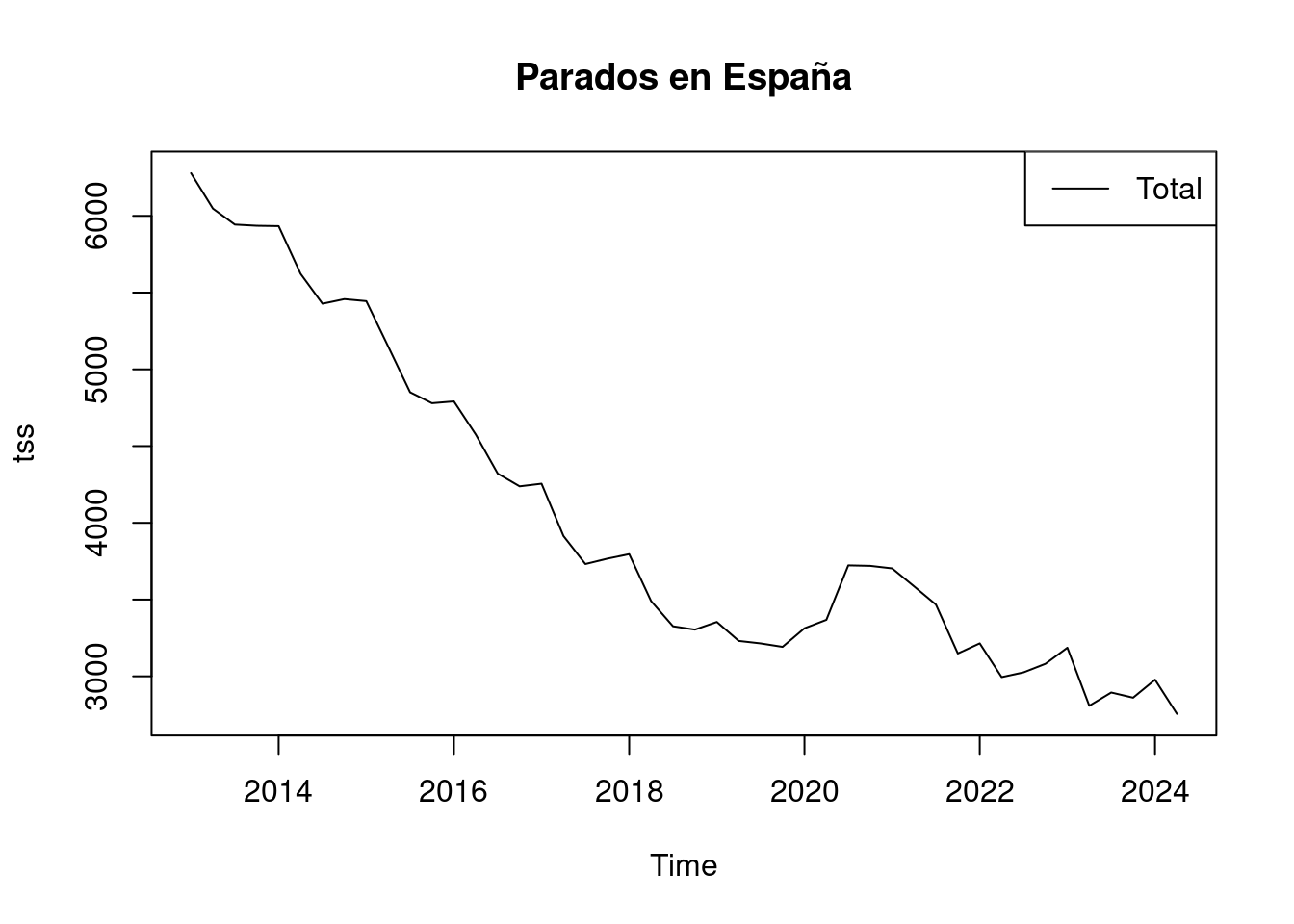
- Tendencia Descendente:
La serie temporal presenta una clara tendencia descendente a lo largo del período analizado. Esto indica que el número de parados ha disminuido de manera consistente con el tiempo.
- Estacionalidad:
Aunque no se observa una estacionalidad clara en el gráfico, es posible que existan patrones estacionales que no sean evidentes a simple vista.
- Variabilidad:
Aunque hay una tendencia general a la baja, existen varias fluctuaciones y picos. Estos picos podrían estar relacionados con eventos específicos, como el COVID, y podrían necesitar un análisis más profundo.
Estabilización Reciente: En los años más recientes (aproximadamente desde 2020), coincidiendo con el COVID la serie aumentó el número de parados para después mostrar cierta estabilización, con variaciones más pequeñas en comparación con los años anteriores. Esto podría indicar que la tendencia a la baja se está ralentizando o que el número de parados está alcanzando un valor estable.
Posibles Cambios Estructurales:
La serie podría tener posibles cambios estructurales, especialmente alrededor de 2020, donde se observa un cambio en la variabilidad. Es relevante considerar estos cambios al modelar, ya que pueden afectar la precisión del modelo ARIMA
Modelo
Sabiendo que los datos tienen frecuencia trimestral y siendo razonable pensar que puede haber una componente estacional ya que de cara a verano se crean más puestos de trabajo (temporales), que luego se destruyen, vamos a considerar un Seasonal ARIMA. Dibujamos la serie de nuevo a ver si es necesario diferenciar una vez más para eliminar la tendencia.
En primer lugar, como hemos comentado, parece razonable tener en cuenta la componente estacional luego diferenciamos un número de veces igual al periodo de los datos
# Series diferenciadas
t1 <- diff(tss, 4)
plot(t1)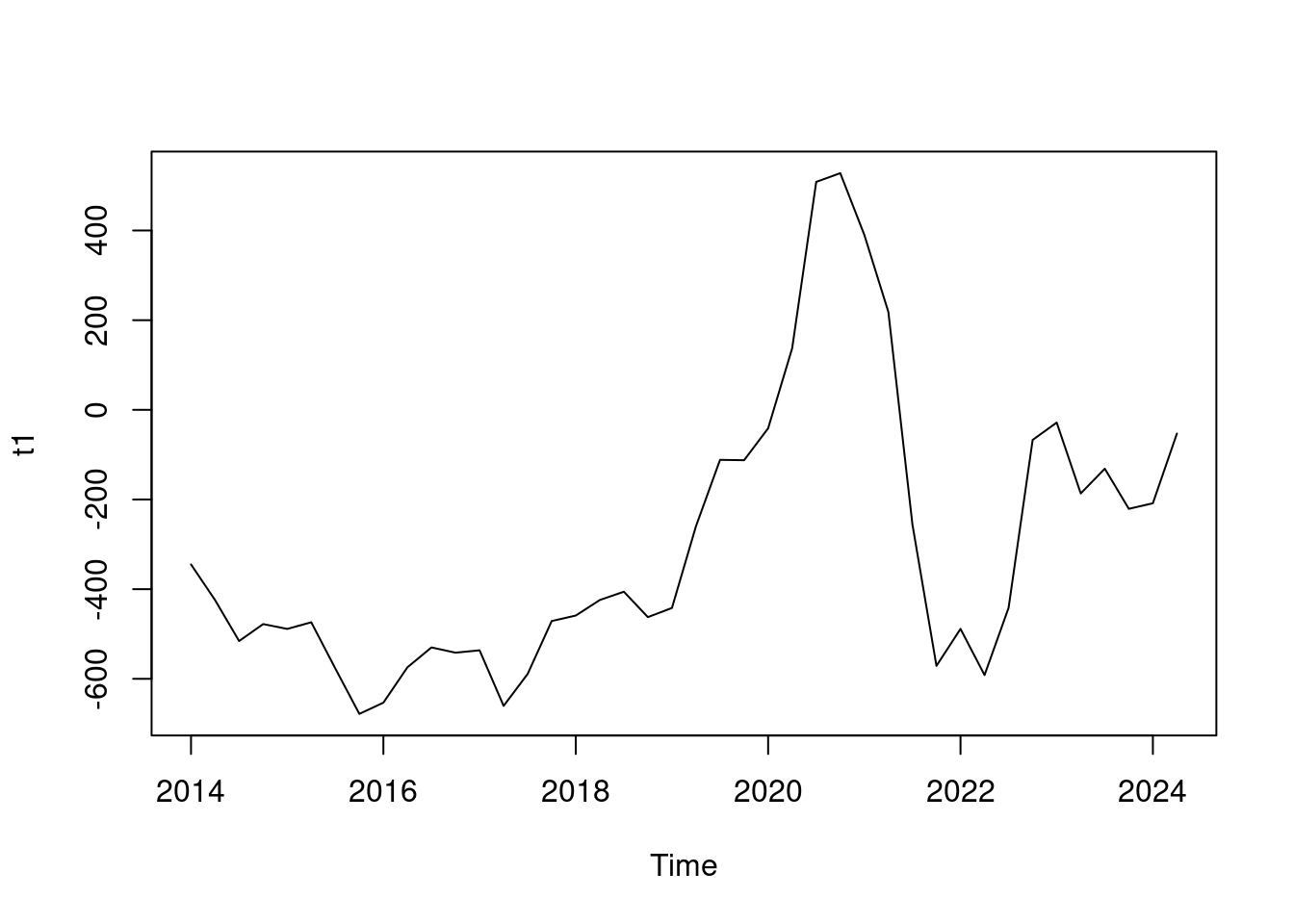
# TEST para ver estacionaridad
# H0= NO es estacionaria
# hace uso del paquete tseries
adf.test(t1, alternative = "stationary")
Augmented Dickey-Fuller Test
data: t1
Dickey-Fuller = -3.275, Lag order = 3, p-value = 0.08903
alternative hypothesis: stationaryNo es estacionaria luego valoramos el diferenciar una vez para ver si conseguimos la estacionaridad.
# Diferenciar
t2 <- diff(t1, 1)
# La dibujamos
plot(t2)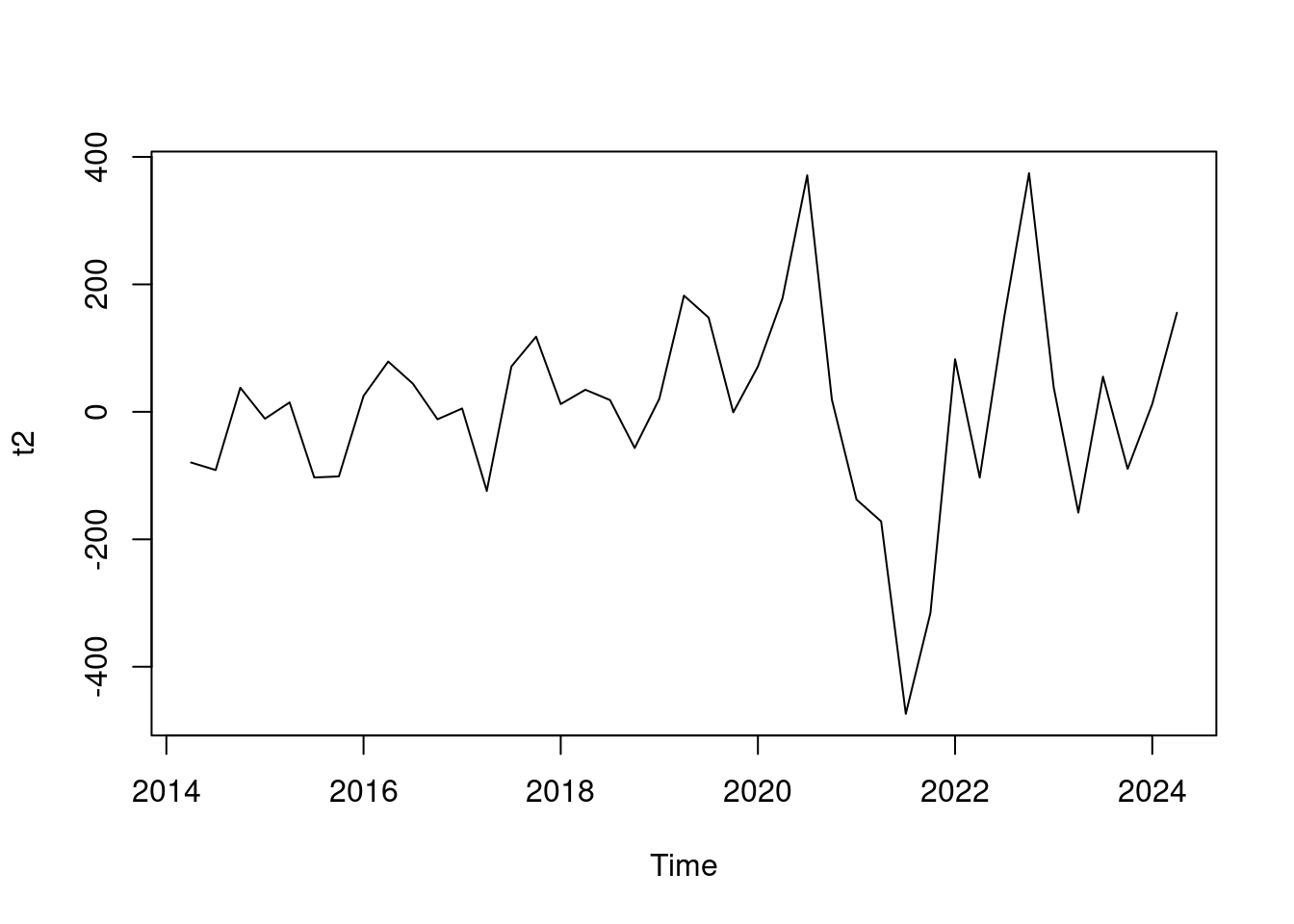
# TEST para ver estacionaridad
# H0= NO es estacionaria
# hace uso del paquete tseries
adf.test(t2, alternative = "stationary")
Augmented Dickey-Fuller Test
data: t2
Dickey-Fuller = -4.5648, Lag order = 3, p-value = 0.01
alternative hypothesis: stationaryAl trazar la serie diferenciada, ya vemos un patrón oscilante alrededor de 0, sin una tendencia fuerte visible. Esto sugiere que la diferenciación es suficiente y debe incluirse en el modelo. Además el test de estacionariedad ya lo pasa.
Es decir, tomamos D=1, d=1. Examinemos ahora ACF/PACF para determinar los p,q y P,Q.
# ACF plot
Acf(t2, main = "ACF para la serie estacionaria", lag.max = 50, ylim = c(-0.5, 0.5))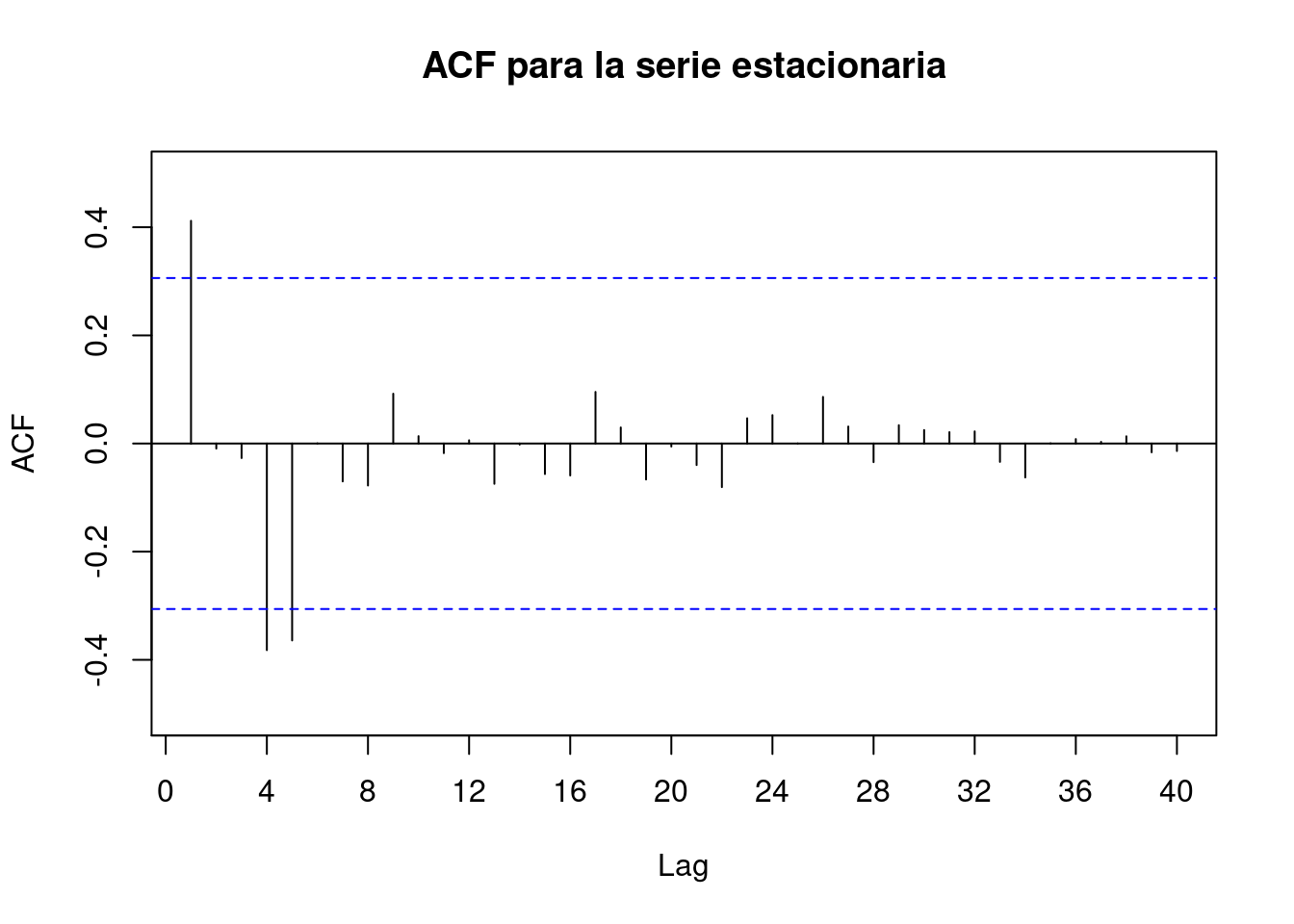
Primeros Lags (parámetros NO estacionales)En el gráfico de ACF vemos que para lag=1 la barra se sale notablemente del límite deseado, reduciéndose en las sucesivas, luego podríamos tomaríamos como q= 1.
Lags múltiplos de 4 (parámetros estacionales) En el gráfico de ACF vemos que para el lag=4 la barra que se sale del límite deseado, no así para lag=8,16,.. (múltiplos m=4 ), luego tomaríamos como Q= 1.
# PACF plot
Pacf(t2, main = "PACF para la serie estacionaria", lag.max = 50, ylim = c(-0.5, 0.5))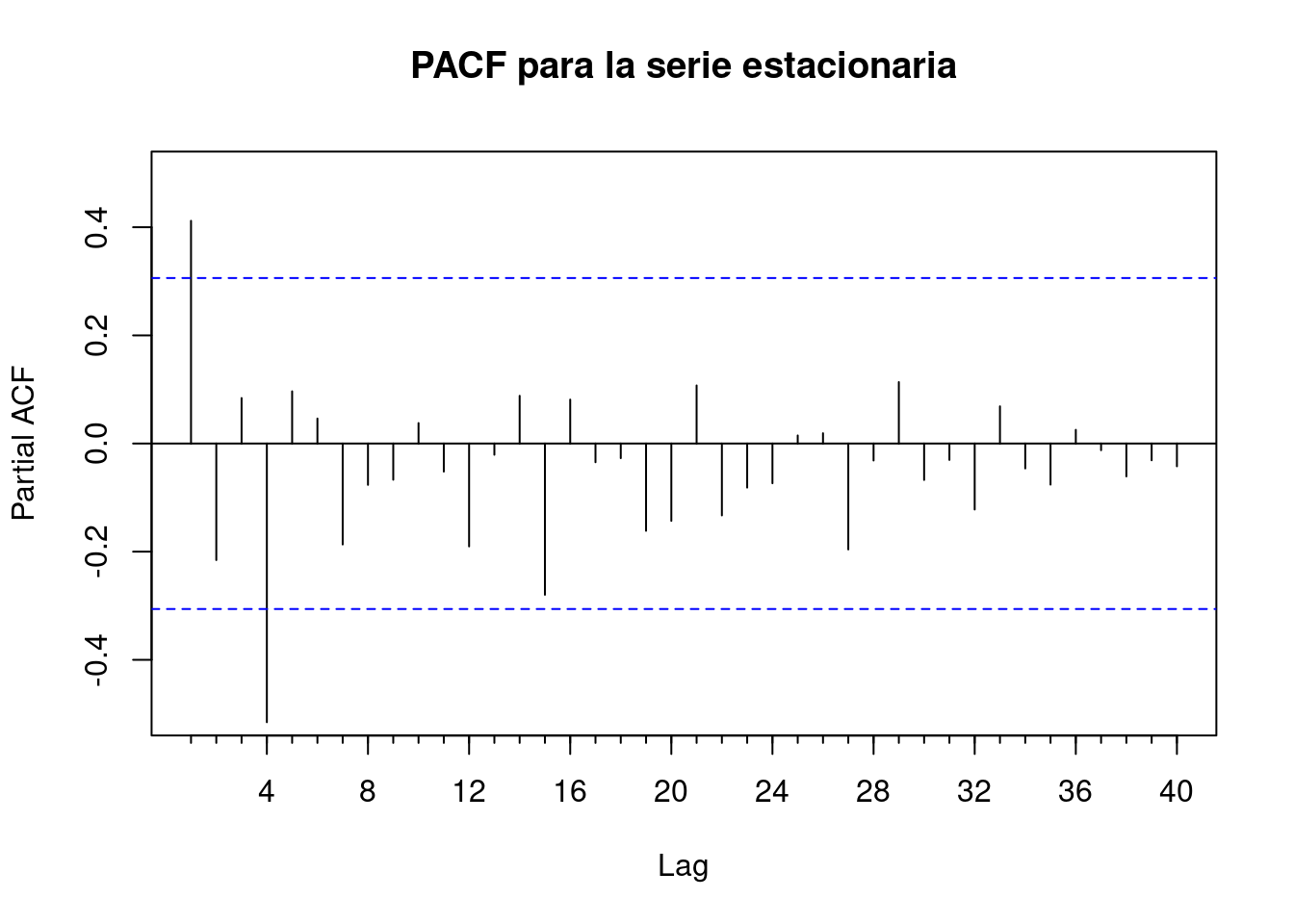
Primeros Lags (parámetros NO estacionales)En el gráfico de PACF vemos que para lag=1 la barra se sale notablemente del límite deseado, reduciéndose en las sucesivas, luego podríamos tomaríamos como q= 1.
Lags múltiplos de 12 (parámetros estacionales) En el gráfico de PACF vemos que para el lag=4 la barra que se sale del límite deseado, no así para lag=8,16,.. (múltiplos m=4 ), luego tomaríamos como P= 1.
Plantear modelos
De acuerdo con lo comentado anteriormente parece razonable tomar el modelo ARIMA(1,1,1)(1,1,1)4
# Ajustar el modelo ARIMA
# Modelo seleccionado
arima_model_1 <- arima(tss, order = c(1, 1, 1), seasonal = c(1, 1, 1))
arima_model_1
Call:
arima(x = tss, order = c(1, 1, 1), seasonal = c(1, 1, 1))
Coefficients:
ar1 ma1 sar1 sma1
-0.0220 0.4914 0.1553 -0.5914
s.e. 0.2662 0.2469 0.3364 0.3254
sigma^2 estimated as 14079: log likelihood = -254.68, aic = 519.36summary(arima_model_1)
Call:
arima(x = tss, order = c(1, 1, 1), seasonal = c(1, 1, 1))
Coefficients:
ar1 ma1 sar1 sma1
-0.0220 0.4914 0.1553 -0.5914
s.e. 0.2662 0.2469 0.3364 0.3254
sigma^2 estimated as 14079: log likelihood = -254.68, aic = 519.36
Training set error measures:
ME RMSE MAE MPE MAPE MASE
Training set 7.123907 112.0401 81.84408 0.2562595 2.371014 0.6291719
ACF1
Training set 0.007450536checkresiduals(arima_model_1)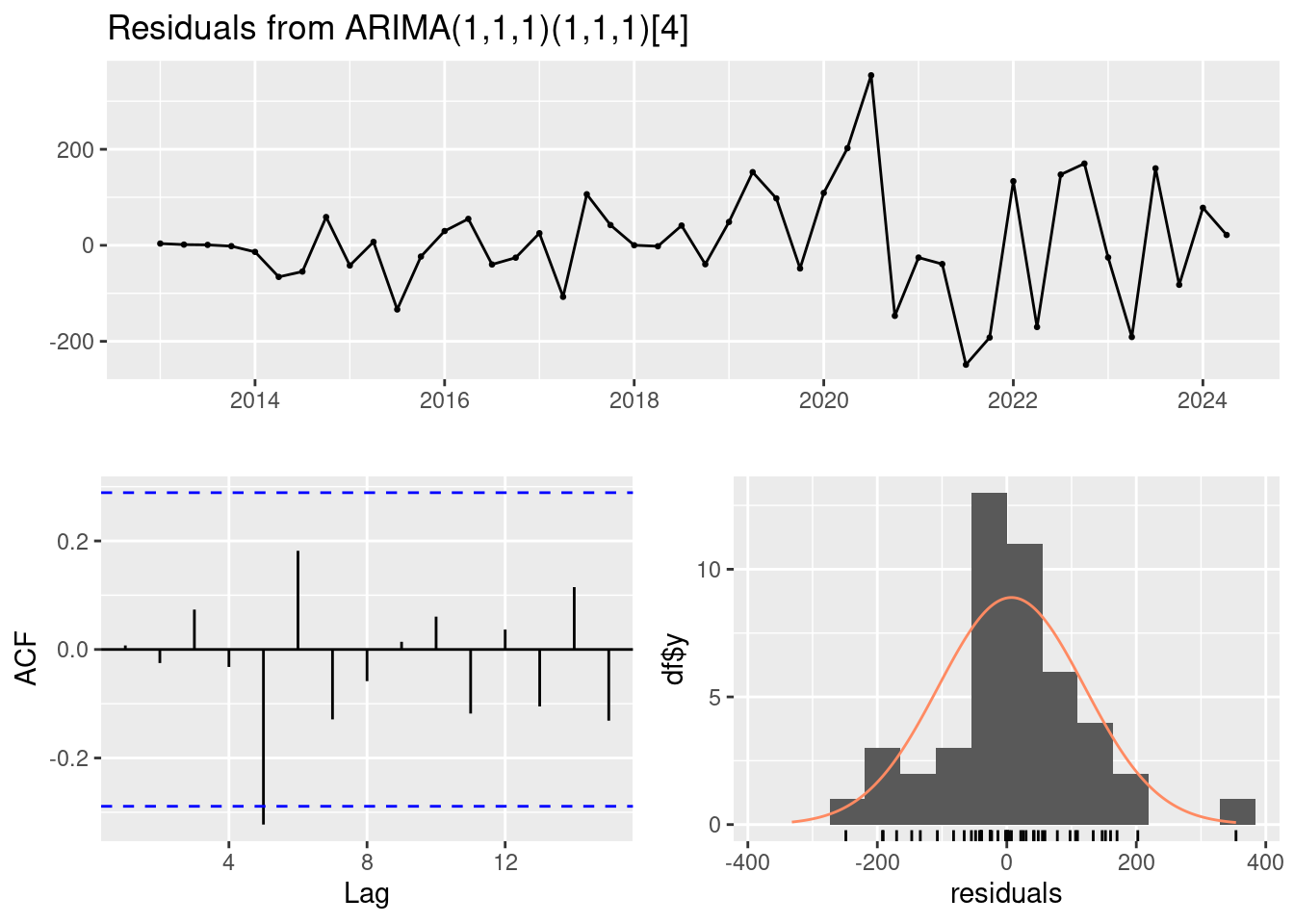
Ljung-Box test
data: Residuals from ARIMA(1,1,1)(1,1,1)[4]
Q* = 8.9359, df = 4, p-value = 0.06272
Model df: 4. Total lags used: 8Box.test(residuals(arima_model_1), type = "Ljung-Box")
Box-Ljung test
data: residuals(arima_model_1)
X-squared = 0.0027237, df = 1, p-value = 0.9584- El Ljung-Box test tiene un p_val>0.05 luego podemos aceptar H0 y asumir que los errores son independientes. Habría que ver para otros modelos.
- Gráfico Residuos vs. Índice: Este gráfico muestra los residuos en función del índice de las observaciones. Idealmente, los residuos deberían estar dispersos alrededor de cero sin ningún patrón discernible (parece que si lo están).
- Gráfico Autocorrelación de Residuos: muestra la autocorrelación de los residuos a diferentes rezagos. Se espera que los residuos no estén correlacionados entre sí. La mayoría de los rezagos no son significativos, lo que sugiere que los residuos no tienen autocorrelación significativa.
- Histograma de Residuos: Muestra la distribución de los residuos. Los residuos parecen estar centrados en torno a cero (aunque hay algunos picos pronunciados) y se aproximan a una distribución normal, lo cual es deseable.
Ahora vamos a proponer ligeras modificaciones en los parámetros del modelo a ver si obtenemos mejores resultados haciendo variar dichos parámetros.
# Combinaciones para parámetros ARIMA
order_list <- list(
"p" = seq(0, 2),
"d" = 1,
"q" = seq(0, 2)
) %>%
cross() %>%
map(lift(c))
# Combinaciones para parámetros estacionales
season_list <- list(
"P" = seq(0, 1),
"D" = 1,
"Q" = seq(0, 1)
) %>%
cross() %>%
map(lift(c))
# Combinar los anteriores
complete <- list(order_list, season_list) %>%
cross() %>%
map(lift(c))
# Inicializamos el dataframe que guarda las métricas
metrics_arima <- data.frame(p = integer(), d = integer(), q = integer(), P = integer(), D = integer(), Q = integer(), MAPE = numeric(), RMSE = numeric(), AIC = numeric())
# Evaluamos todos los modelos con las combinaciones
for (i in c(1:length(complete))) {
# Los que dan error los quitamos
arimaa <- arima(tss, order = complete[[i]][1:3], seasonal = complete[[i]][4:6])
MAPE <- mean(abs((tss - fitted(arimaa)) / tss)) * 100
RMSE <- sqrt(mean((tss - fitted(arimaa))^2))
metrics_arima[i, ] <- c(c(complete[[i]]), MAPE, RMSE, summary(arimaa)[["aic"]])
}
# Quitamos las observaciones que tienen valores nulos
metrics_arima <- na.omit(metrics_arima)
metrics_arima <- metrics_arima[order(metrics_arima$AIC), ]
# Mostramos los resultados
knitr::kable(metrics_arima)| p | d | q | P | D | Q | MAPE | RMSE | AIC | |
|---|---|---|---|---|---|---|---|---|---|
| 27 | 2 | 1 | 2 | 0 | 1 | 1 | 1.824499 | 98.52474 | 514.6145 |
| 22 | 0 | 1 | 1 | 0 | 1 | 1 | 2.381759 | 112.47135 | 515.5862 |
| 13 | 0 | 1 | 1 | 1 | 1 | 0 | 2.484048 | 115.37288 | 517.2650 |
| 31 | 0 | 1 | 1 | 1 | 1 | 1 | 2.375174 | 112.03060 | 517.3646 |
| 25 | 0 | 1 | 2 | 0 | 1 | 1 | 2.376143 | 112.45542 | 517.5592 |
| 23 | 1 | 1 | 1 | 0 | 1 | 1 | 2.377129 | 112.45752 | 517.5623 |
| 20 | 1 | 1 | 0 | 0 | 1 | 1 | 2.355598 | 114.73773 | 517.5780 |
| 21 | 2 | 1 | 0 | 0 | 1 | 1 | 2.352555 | 113.64722 | 518.6770 |
| 4 | 0 | 1 | 1 | 0 | 1 | 0 | 2.545648 | 120.75934 | 518.7198 |
| 29 | 1 | 1 | 0 | 1 | 1 | 1 | 2.380937 | 113.14800 | 518.8496 |
| 26 | 1 | 1 | 2 | 0 | 1 | 1 | 2.322109 | 110.24799 | 518.9644 |
| 16 | 0 | 1 | 2 | 1 | 1 | 0 | 2.466333 | 115.16374 | 519.1214 |
| 14 | 1 | 1 | 1 | 1 | 1 | 0 | 2.469534 | 115.17743 | 519.1301 |
| 34 | 0 | 1 | 2 | 1 | 1 | 1 | 2.370649 | 112.04161 | 519.3571 |
| 32 | 1 | 1 | 1 | 1 | 1 | 1 | 2.371014 | 112.04007 | 519.3578 |
| 24 | 2 | 1 | 1 | 0 | 1 | 1 | 2.364762 | 112.39329 | 519.5076 |
| 17 | 1 | 1 | 2 | 1 | 1 | 0 | 2.369324 | 111.61460 | 519.8802 |
| 8 | 1 | 1 | 2 | 0 | 1 | 0 | 2.405546 | 115.61033 | 520.0355 |
| 30 | 2 | 1 | 0 | 1 | 1 | 1 | 2.367857 | 112.53661 | 520.1042 |
| 7 | 0 | 1 | 2 | 0 | 1 | 0 | 2.537381 | 120.52312 | 520.5438 |
| 5 | 1 | 1 | 1 | 0 | 1 | 0 | 2.541460 | 120.53131 | 520.5466 |
| 11 | 1 | 1 | 0 | 1 | 1 | 0 | 2.559854 | 121.00635 | 520.9394 |
| 15 | 2 | 1 | 1 | 1 | 1 | 0 | 2.451736 | 115.09807 | 521.0804 |
| 19 | 0 | 1 | 0 | 0 | 1 | 1 | 2.227996 | 122.44482 | 521.2291 |
| 33 | 2 | 1 | 1 | 1 | 1 | 1 | 2.362370 | 112.02718 | 521.3299 |
| 35 | 1 | 1 | 2 | 1 | 1 | 1 | 2.370299 | 112.04173 | 521.3561 |
| 12 | 2 | 1 | 0 | 1 | 1 | 0 | 2.534603 | 119.10918 | 521.6933 |
| 18 | 2 | 1 | 2 | 1 | 1 | 0 | 2.367991 | 111.64051 | 521.8769 |
| 9 | 2 | 1 | 2 | 0 | 1 | 0 | 2.408823 | 115.74212 | 522.0103 |
| 28 | 0 | 1 | 0 | 1 | 1 | 1 | 2.229198 | 120.36548 | 522.4966 |
| 6 | 2 | 1 | 1 | 0 | 1 | 0 | 2.530760 | 120.50559 | 522.5368 |
| 36 | 2 | 1 | 2 | 1 | 1 | 1 | 2.316717 | 110.10590 | 522.8850 |
| 2 | 1 | 1 | 0 | 0 | 1 | 0 | 2.820368 | 129.15689 | 523.8542 |
| 3 | 2 | 1 | 0 | 0 | 1 | 0 | 2.722357 | 125.95327 | 523.8909 |
| 10 | 0 | 1 | 0 | 1 | 1 | 0 | 2.548782 | 131.13138 | 525.4774 |
| 1 | 0 | 1 | 0 | 0 | 1 | 0 | 2.748537 | 142.27674 | 529.5991 |
En este caso de acuerdo a las métricas observadas (mirando principalmente un menor AIC) parece razonable seleccionar el ARIMA(2,1,2)(0,1,1) como el mejor modelo, aunque parece un poco complejo. Acto seguido aparece el ARIMA(0,1,1)(0,1,1). Comprobemos también con la función auto.arima() , la cual nos devuelve los parámetros óptimos de manera automática.
auto.arima(tss)Series: tss
ARIMA(0,1,1)(0,1,1)[4]
Coefficients:
ma1 sma1
0.4958 -0.4556
s.e. 0.1510 0.1833
sigma^2 = 14920: log likelihood = -254.79
AIC=515.59 AICc=516.23 BIC=520.73Luego parece razonable quedarnos con el ARIMA(0,1,1)(0,1,1). Examinemos qué tal es el modelo:
# Modelo seleccionado
arima_model_4 <- arima(tss, c(0, 1, 1), c(0, 1, 1))
# Serie junto a modelo
plot(tss, col = "blue")
lines(fitted(arima_model_4), col = "red")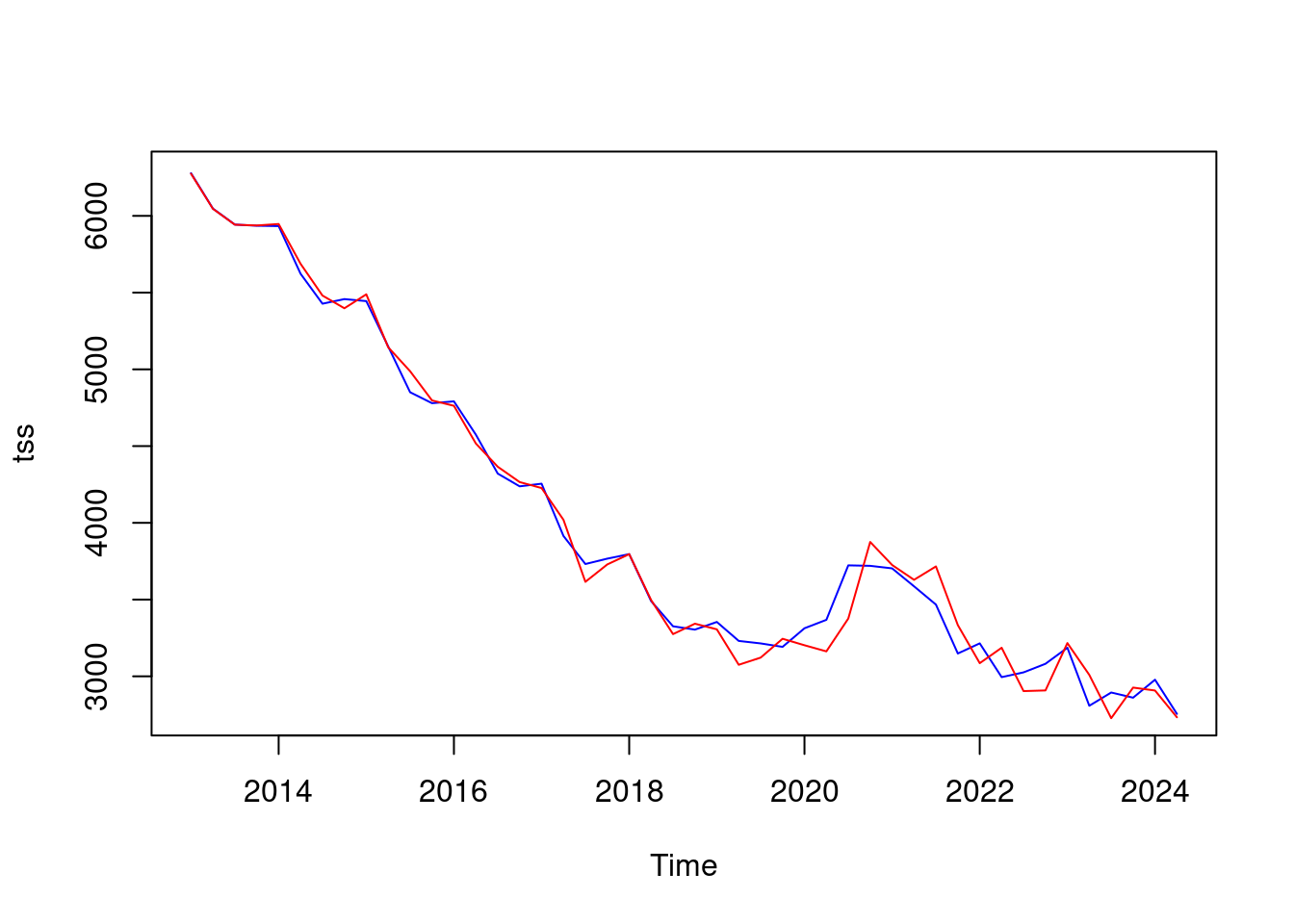
# Diagnóstico del modelo
checkresiduals(arima_model_4)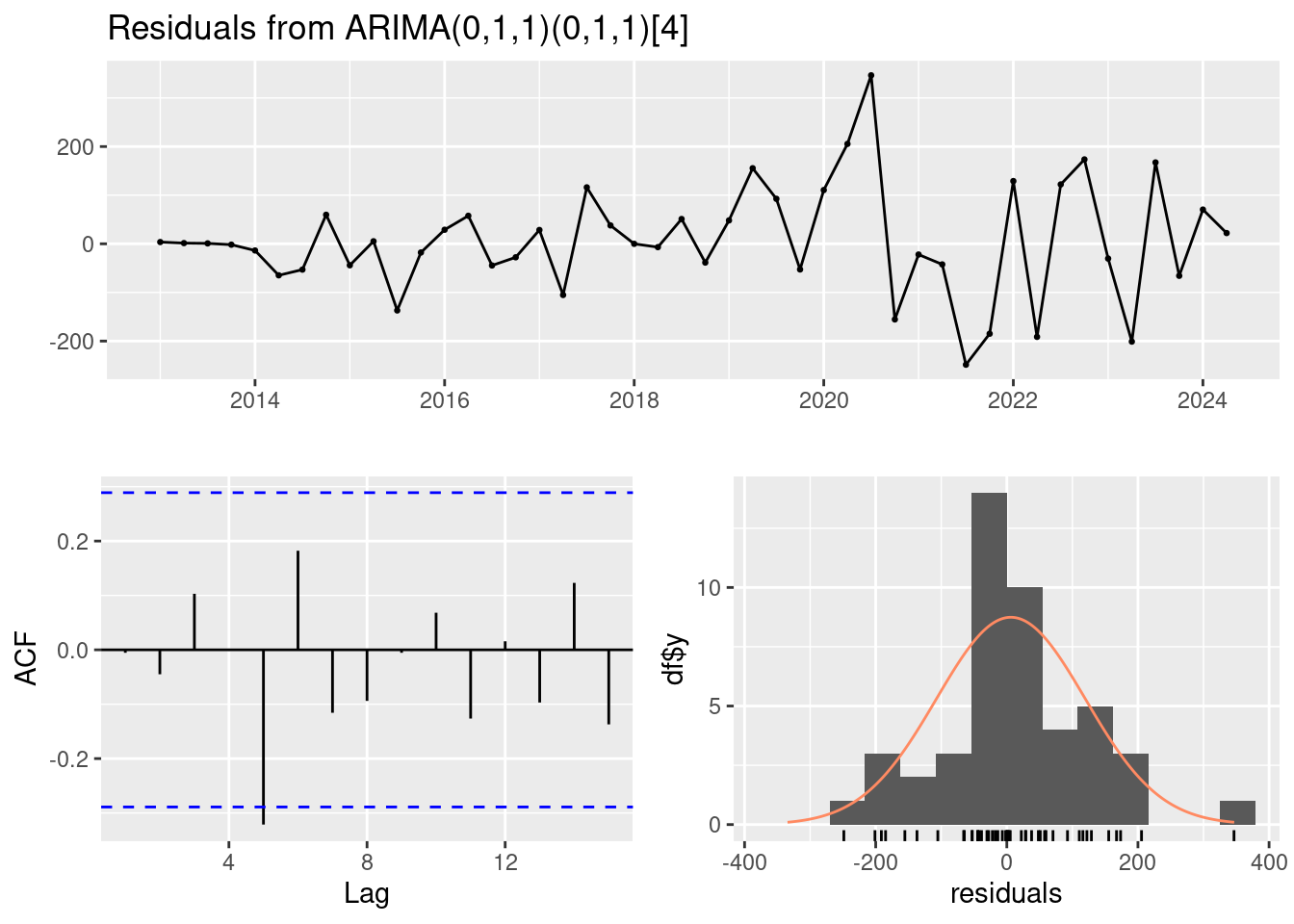
Ljung-Box test
data: Residuals from ARIMA(0,1,1)(0,1,1)[4]
Q* = 9.3113, df = 6, p-value = 0.1568
Model df: 2. Total lags used: 8# H0: no hay autocorrelación residual en los residuos del model
# Queremos ver que se prueba H0
Box.test(residuals(arima_model_4), type = "Ljung-Box")
Box-Ljung test
data: residuals(arima_model_4)
X-squared = 0.0014225, df = 1, p-value = 0.9699# Aceptamos H0 puesto que es >0.05De nuevo, - El Ljung-Box test tiene un p_val>0.05 luego podemos aceptar H0 y asumir que los errores son independientes. Habría que ver para otros modelos. - Gráfico Residuos vs. Índice: Este gráfico muestra los residuos en función del índice de las observaciones. Idealmente, los residuos deberían estar dispersos alrededor de cero sin ningún patrón discernible (parece que si lo están). - Gráfico Autocorrelación de Residuos: muestra la autocorrelación de los residuos a diferentes rezagos. Se espera que los residuos no estén correlacionados entre sí. La mayoría de los rezagos no son significativos, lo que sugiere que los residuos no tienen autocorrelación significativa. - Histograma de Residuos: Muestra la distribución de los residuos. Los residuos parecen estar centrados en torno a cero (aunque hay algunos picos pronunciados) y se aproximan a una distribución normal, lo cual es deseable.
En consecuencia, los pronósticos de este método probablemente serán buenos.
Ahora, una vez seleccionados los parámetros, vamos a construir el modelo con todos datos menos las últimas 6 observaciones y vamos a predecir a ver que tal es.
# creamos train/test partición
data.train <- window(tss, end = c(2022, 4))
data.test <- window(tss, start = c(2023, 1))
# Modelo
# Cogemos esos parámetros porque los otros dan error
arima_model_4 <- arima(data.train, c(1, 1, 1), c(1, 1, 0))
pred <- forecast(arima_model_4, h = 6)
accuracy(pred, data.test) ME RMSE MAE MPE MAPE MASE
Training set 4.69072 114.1325 82.21041 0.191017 2.296659 0.1915248
Test set -119.17935 134.2443 119.17935 -4.161533 4.161533 0.2776509
ACF1 Theil's U
Training set 0.0172511 NA
Test set -0.2926606 0.7155813# Gráfico con los datos originales y las predicciones de los modelos
plot(tss,
xlim = c(2013, 2025), ylim = c(min(tss, pred$pred), max(tss, pred$pred)),
xlab = "Fecha", ylab = "Valor", main = "Comparación de Predicciones ARIMA"
)
points(pred$mean, col = "purple", pch = 16, cex = 0.5) # Predicciones con arima_model1 en rojo
lines(tss, col = "blue", lwd = 2) # Serie original en azul
lines(fitted(arima_model_4), col = "red")
legend("topright", legend = c("Original", "ARIMA Modelo ", "Predicción"), col = c("blue", "red", "purple"), lty = 1)
lines(pred$lower[, 2], col = "purple", lty = "solid")
lines(pred$upper[, 2], col = "purple", lty = "solid")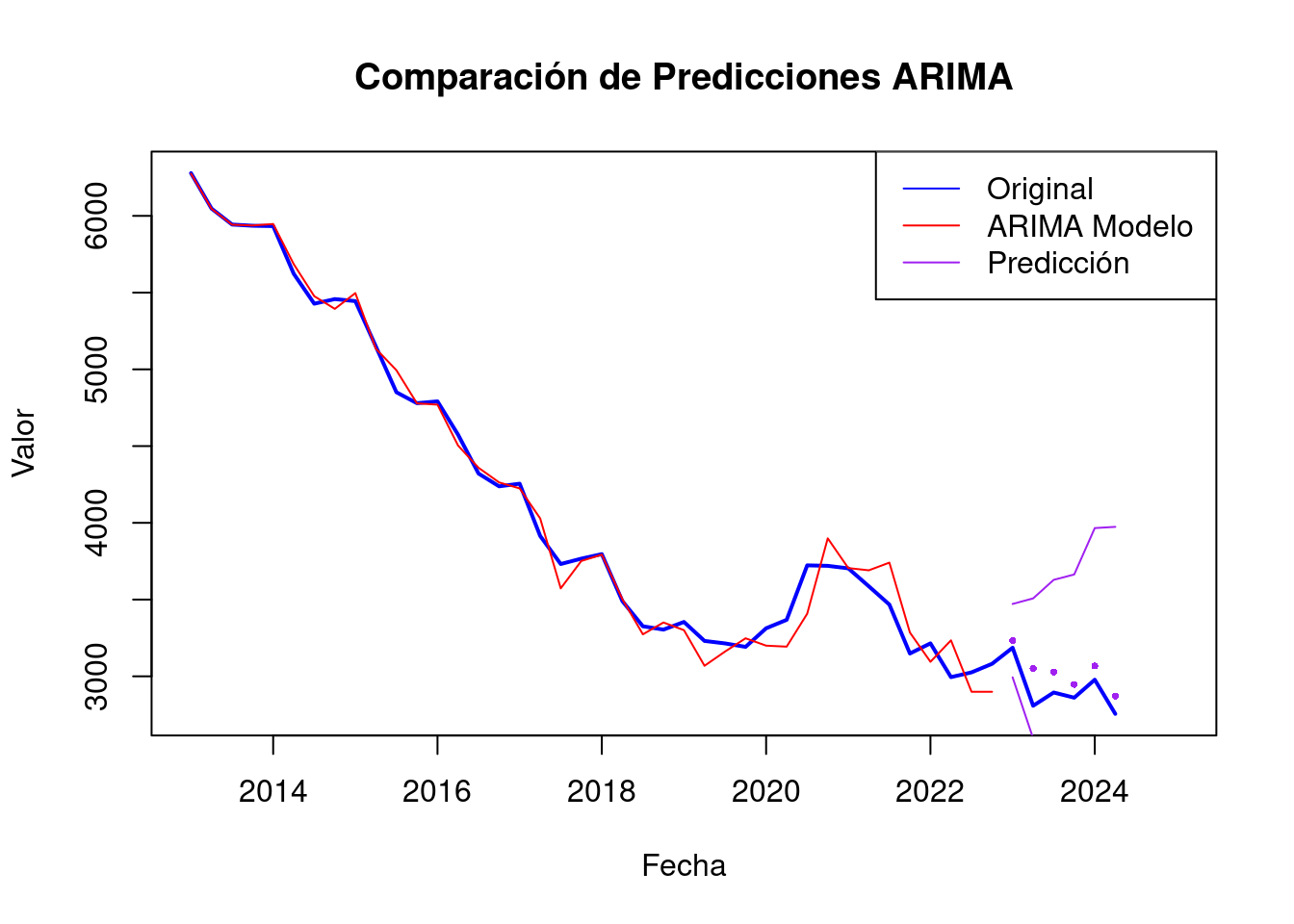
Tenemos un MAPE del 4%, que es una desviación ligera.
ARIMA automático
Existe una función, ya comentada, que permite identificar los parámetros de manera automática. Generalmente se suele usar como primer approach está función para después modificar según evidencia los parámetros.
# Identificar los parámetros del modelo ARIMA de manera automática
auto_arima <- auto.arima(tss)
auto_arimaSeries: tss
ARIMA(0,1,1)(0,1,1)[4]
Coefficients:
ma1 sma1
0.4958 -0.4556
s.e. 0.1510 0.1833
sigma^2 = 14920: log likelihood = -254.79
AIC=515.59 AICc=516.23 BIC=520.73Notar que nos propone ARIMA(1,1,1)(1,0,0)[4], que es el modelo que hemos usado previamente.
El modelo seleccionado por nosotros parece un buen modelo y que predice con poco error. Este era muy cercano all detectado automáticamente por R, luego esto evidencia que como primer approach se puede usar la función auto.arima() obteniendo buenos resultados. No obstante es aconsejable estudiar el problema más a fondo para estudiar todas las posibles modelizaciones y tomar la que mejor se ajuste a nuestras expectativas.
Conclusión
A lo largo de este notebook se ha expuesto las principales característica de una serie temporal y se ha explicado como modelarla mediante un modelo ARIMA, explicando además la ampliación de este tipo de modelos a los SARIMA (ARIMA estacional) y todas las consideraciones a tener en cuenta.